本文主要是通过解析页面来提取各条微博的内容和相关信息。
提取页面
下面是一个微博页面的源码段,微博页面采用 BigPipe 网页加载模式,使用 FM.view() 对页面分块加载,让你能更快的看到内容。
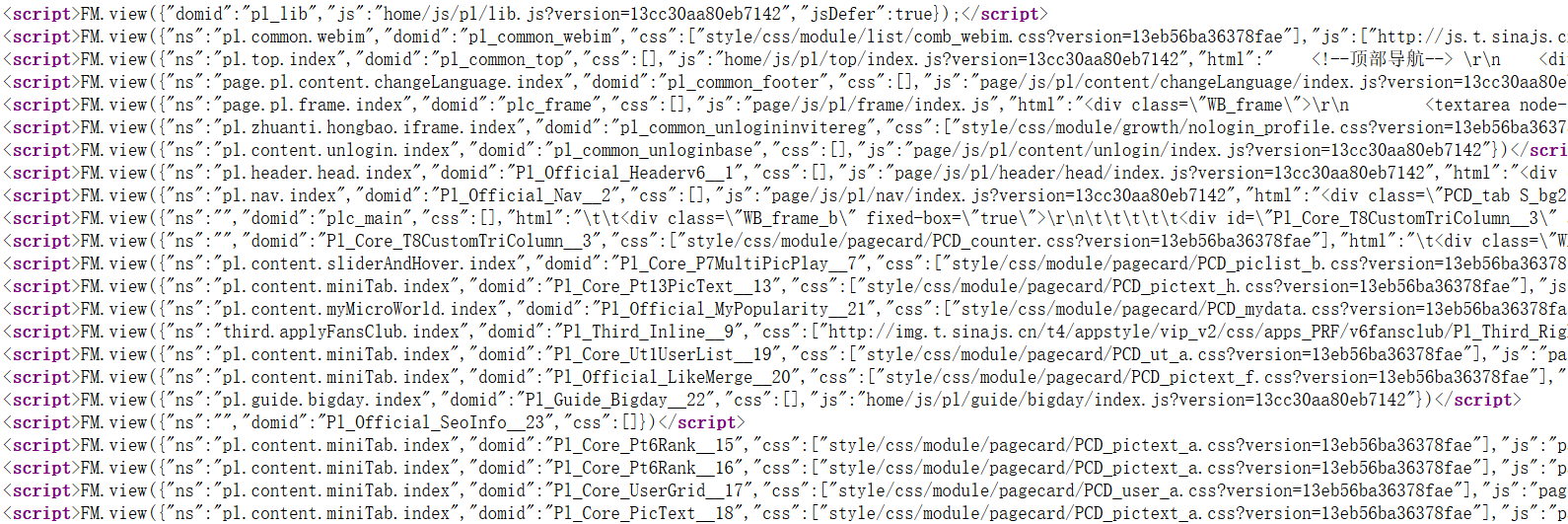
这种页面加载模式导致不能直接使用HTML解析器去提取各条微博,使用正则表达式提取的话,工作量又太大。
Ctrl + F 微博正文可以找出各条微博内容都在 <script>FM.view({"ns":"pl.content.homeFeed.index" 开头的那一行 js 中,这段字符串就是要操作的对象。
观察过后发现 FM.view() 内使用的 Json 格式,果断尝试使用 Newtonsoft.Json 对其中的数据进行反序列化。
先写一个对应其格式的类,格式可以用 在线解析器 查看
1 2 3 4 5 6 7 8 9 10 11
| public class ViewJson { public string ns { get; set; } public string domid { get; set; } public string[] css { get; set; } public string js { get; set; } public string html { get; set; } }
|
然后直接使用 Newtonsoft.Json 提供的 JsonConvert.DeserializeObject<T>() 方法反序列化 Json 数据。viewJson.html 就是我需要的内容(各条微博的信息都在里面)
1 2 3 4
| string jsonStr = jsStr.Replace("<script>FM.view(", "").Replace(")</script>", ""); ViewJson viewJson = JsonConvert.DeserializeObject<ViewJson>(jsonStr);
|
页面解析
C# 解析 HTML 当选 HtmlAgilityPack
找到顶层节点然后使用 XPath 得到自己所需要的数据,这是个体力活,直接给出代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(viewJson.html); HtmlNode topNode = doc.DocumentNode.ChildNodes[1]; List<WeiboFeed> wbFeedList = new List<WeiboFeed>(); foreach (HtmlNode feedListItem in topNode.ChildNodes) { if (feedListItem.Attributes.Contains("action-type") && feedListItem.Attributes["action-type"].Value == "feed_list_item") { string mid = feedListItem.Attributes["mid"].Value; string username = feedListItem.SelectSingleNode("div[1]/div[@class='WB_detail']/div[1]/a[1]").InnerHtml; string time = feedListItem.SelectSingleNode("div[1]/div[@class='WB_detail']/div[2]/a[1]").Attributes["title"].Value; string content = feedListItem.SelectSingleNode("div[1]/div[@class='WB_detail']/div[3]").InnerHtml; WeiboFeed wbFeedTmp = new WeiboFeed(this, mid, username, time, content); wbFeedList.Add(wbFeedTmp); } }
|
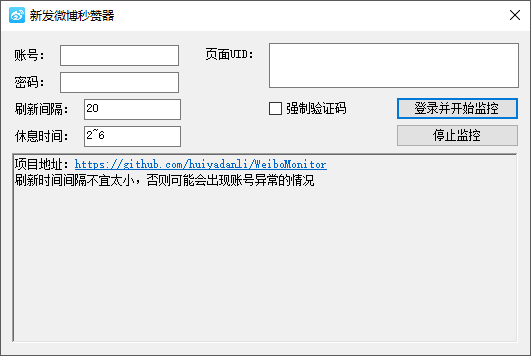
附赠
以上东西的应用:微博秒赞器